- LLMO/GEO分析ツールのAKARUMI(アカルミ)TOP
- AKARUMI Insights
- AIクローラーとは?仕組みと特徴を理解して、最適な対策方法を知ろう
AIクローラーとは?仕組みと特徴を理解して、最適な対策方法を知ろう

生成AIの普及により耳にする機会が増えた「AIクローラー」。正体がよくわからず、不安な方も多いのではないでしょうか。本記事では、AIクローラーの仕組みや特徴から具体的な対策方法までわかりやすく解説します。自社サイトの運営にぜひお役立てください。
Contents
AIクローラーとは?

AIクローラーとは、Web上の情報を収集し、生成AIの学習や回答生成に活用するクローラーです。近年は、ChatGPTやGeminiをはじめとする生成AIの普及によって、AIが参照するWeb情報の需要も高まっています。
その影響から、サイト運営者の間では「どの情報をAIに収集させるか」「どこまで許可・拒否するか」といった対策ニーズも拡大しています。
検索エンジンクローラーとの違い
| 種類 | 主な目的 |
|---|---|
| 検索エンジン | インデックス化が主目的 |
| AIクローラー | 学習・回答生成用データ収集が主目的 |
検索エンジンクローラーは、検索結果へ表示するためのインデックス化を主な目的としています。一方、AIクローラーは、生成AIの学習や回答生成に利用するデータ収集を目的としている点が特徴です。
そのため、AIクローラー対策では、検索順位への影響だけでなく、AIによってどのように情報が利用・引用されるかも考慮する必要があります。AI経由での認知獲得につながる可能性がある一方で、意図しない学習利用や情報流用のリスクも否定できません。
AIクローラーの仕組み
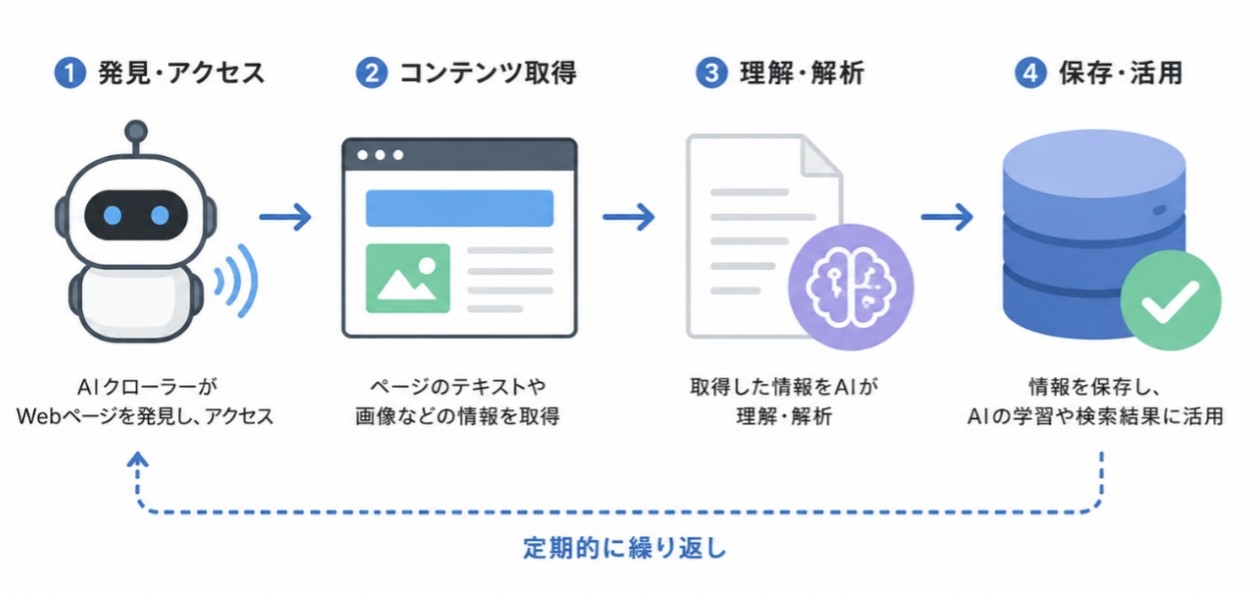
AIクローラーは、WebページのHTMLを読み取りながら情報を収集します。タイトルタグや見出し、本文、リンク情報などを解析し、ページにどのような内容が掲載されているかを理解する仕組みです。さらに、見出しの階層構造や画像のalt属性といった「ページ全体の構成」もチェックしています。
これらの情報は、AIクローラーにとってページのテーマや重要度、関連性を判断する材料です。そのため、サイト構造やマークアップは、クローラーの制御や情報取得に影響する可能性があります。
【収集されやすい情報】
| 項目 | 内容 |
|---|---|
| 本文 | ページ内のテキストコンテンツ |
| 見出し | ページの構造や要点を示す見出し |
| 画像周辺情報 | alt属性、キャプション、ファイル名など |
| ページ構造 | URL、内部リンク、パンくずリスト、構造化データなど |
JavaScriptは認識されない?
AIクローラーは基本的にHTMLをもとに情報を取得します。そのため、JavaScriptによって後から表示されるコンテンツは、正しく認識されない場合があります。
とくに多く見られるのが、本文やリンク、商品情報などの重要な内容をJavaScript依存で表示しているケースです。この場合、AIや検索エンジンが情報を取得しきれない可能性があります。情報を確実に取得させたい場合は、HTMLで出力しましょう。
ただし、主要なAIクローラーはJavaScriptの実行能力を備えているため、これを遮断目的で利用するのは注意が必要です。AIクローラーの遮断をしたい場合は、robots.txtなどによる制御を行いましょう。
主なAIクローラーの種類と特徴
| 提供元 | 用途 | 特徴 | 制御方法 | |
|---|---|---|---|---|
| GPTBot | OpenAI | ChatGPTなどAIモデルの学習・回答生成 | 学習データ収集を目的としたクローラー。Webページの内容を収集し、回答品質向上に活用される。 | robots.txt |
| Google-Extended | Geminiなどの学習・回答生成 | 通常のGooglebotとは異なり、生成AI用途への利用可否を指定するための仕組み。検索順位には直接影響しないとされる。 | robots.txt | |
| ClaudeBot | Anthropic | Claudeの学習・回答生成 | Claude向けにWeb情報を収集するクローラー。比較的新しいため、ログ監視やアクセス傾向の確認が重要。 | robots.txt |
| Bytespider | ByteDance | ByteDance系AI・サービス開発 | TikTok運営元のByteDanceが提供。アクセス頻度や収集範囲について話題になることが多く、ブロック対象として扱われるケースもある。 | robots.txt や WAF など |
AIクローラーにはさまざまな種類があり、提供元や利用目的によって特徴が異なります。
たとえば、GPTBotや ClaudeBotでは、生成AIの学習や回答生成のためにWeb上の情報を収集します。一方、Google-Extendedは、Geminiなど生成AIへの利用可否をサイト運営者側で制御するための仕組みです。
Bytespiderは、ByteDance系サービス向けに情報収集をするクローラーです。Bytespiderについては、アクセス頻度の高さや収集範囲への懸念から、ブロック対象として扱われるケースもあります。
自社サイトに来ているのはどのAIクローラー?
AIクローラーが自社サイトへアクセスしているか確認するには、サーバーログやアクセス解析ツールを活用する方法があります。
とくに確認したいのが「User-Agent」と呼ばれる識別情報です。たとえば、GPTBotやClaudeBotなどは固有のUser-Agentを持っています。そのため、ログを確認することでアクセス状況を把握することが可能です。
また、CloudflareなどのCDN・WAFを導入している場合は、管理画面上でボットのアクセス履歴を確認できるケースもあります。AIクローラーの種類やアクセス頻度を把握することで、許可・拒否の判断や負荷対策につなげられるでしょう。
AIクローラーがECサイトに与える影響
| メリット | デメリット |
|---|---|
| ・AI経由で商品やブランドが認知される ・比較検討段階のユーザーに接触しやすくなる ・良質なコンテンツが評価されやすくなる |
・「ゼロクリック検索」でサイト流入が減少する ・商品情報だけ取得されるリスクがある ・サーバー負荷が増える場合がある ・情報の文脈が失われる場合がある |
AIクローラーの普及により、ECサイトはAI経由で商品やブランドを認知される機会が増えています。また、比較検討段階のユーザーへ情報が届きやすくなる点もメリットの一つです。
一方で、AI検索で情報取得が完結し、サイト流入が減少する「ゼロクリック検索」のリスクもあります。商品情報のみが引用されてブランド訴求が弱まったり、クロールの増加によってサーバー負荷が高まったりする可能性も否定できません。
それぞれのAIクローラーの特性を理解したうえで、適切な対策を行いましょう。
ECサイト・メディアサイトで影響が大きい理由
ECサイトやメディアサイトがAIクローラーの影響を受けやすい傾向にあるのは、商品情報や記事コンテンツなど、大量のテキストデータを保有しているためです。
ECサイトでは、とくに商品説明やレビュー情報がAI回答に利用される可能性が高くなります。メディアサイトでは、独自記事や比較コンテンツが引用対象になりやすい傾向にあります。
AIクローラーを制御・ブロックする4つの方法
AIクローラーは、robots.txtやメタタグ、サーバー設定などを利用することで制御できます。ただ全面的に拒否してしまうと、AI経由での認知獲得や引用機会を失う可能性もあります。用途や公開範囲に応じて柔軟に管理することが大切です。
robots.txtで制御する
robots.txtは、特定のクローラーに対してアクセス可否を伝えるための設定ファイルです。たとえば「GPTBot」や「ClaudeBot」などのUser-agentを指定することで、AIクローラーごとにクロール可否を制御できます。
比較的導入しやすい方法ですが、あくまでクローラー側の自主的な遵守に依存するため、強制的に遮断できるわけではありません。
メタタグで制御する
メタタグを利用すると、ページ単位でAIクローラーへの対応を調整できます。たとえば、特定ページのみインデックス対象から除外したい場合や、AI利用を制限したい場合に活用されます。
サイト全体を対象とするrobots.txtとは異なり、より細かく設定できる点が特徴です。用途に応じて、robots.txtと使い分けるとよいでしょう。
.htaccessやサーバー設定で遮断する
より強くAIクローラーを制御したい場合は、.htaccessやサーバー設定による遮断方法があります。特定のIPアドレスやUser-Agentを指定してアクセスを拒否できるため、robots.txtより強制力が高い点が特徴です。
ただし、設定内容によっては通常ユーザーや検索エンジンにも影響を与える可能性もあるため、慎重に運用する必要があります。
WAF・CDN・セキュリティサービスを活用する
AIクローラーによる大量アクセスや不審な通信への対策としては、WAFやCDN、セキュリティサービスの活用も有効です。たとえばCloudflareでは、Bot管理機能を利用してアクセス制御や監視を行えます。
サーバー負荷の軽減や異常アクセス対策にもつながるため、大規模サイトやECサイトでは導入を検討する価値があるでしょう。
AIクローラーは拒否すべき?許可すべき?

AIクローラーを拒否すべきか、許可すべきか迷っている方も多いのではないでしょうか。自社コンテンツの価値や流入戦略、AI経由での認知獲得などを踏まえながら、目的に応じた方針を検討しましょう。
拒否したほうがよいケース
AIクローラーの拒否を検討すべきなのは、AIサービスによるコンテンツ利用が事業上の不利益につながる可能性がある場合です。
たとえば、有料コンテンツや会員限定情報、独自調査データなどがあり、AIによる学習や回答生成への利用によってコンテンツの価値が損なわれる懸念があるケースが挙げられます。
また、AIクローラーによるアクセスが増加し、サーバー負荷や運用コストに影響が生じている場合も、アクセス制限を検討してもよいでしょう。
判断基準
許可したほうがよいケース
AI経由での商品認知やブランド接触を強化したい場合は、AIクローラーの許可を検討しましょう。
近年は、AI検索や生成AIを利用して情報収集を行うユーザーが増えています。AI回答内で自社商品やコンテンツが紹介されることで、比較検討段階のユーザーと接触できる可能性もあります。
LLMOやAIOを見据える場合は、一部コンテンツを戦略的に公開する運用も有効です。
判断基準
 監修者コメント
監修者コメント
判断に迷う場合は、全面的な拒否よりも「ページ単位・ディレクトリ単位」での段階的な制御が現実的です。目的別に公開範囲を分けることで、リスクと機会のバランスを取りやすくなります。
AIクローラーとSEO・LLMO/AIOの関係
| SEO | LLMO/AIO | AIクローラー対策 | |
|---|---|---|---|
| 主な目的 | 検索順位向上 | AI回答での引用・露出 | AIによる情報収集の制御 |
| 対象 | 検索エンジン | 生成AI | AIクローラー |
| 重視するポイント | 検索流入 | AI経由の認知 | 情報利用の管理 |
| 主な施策 | コンテンツ最適化、内部対策 | AIが理解しやすい構造化 | robots.txt、WAF設定など |
SEO、LLMO/AIO、AIクローラー対策は、それぞれ役割や目的が異なります。近年は、検索エンジンだけではなく、生成AIを使った情報収集が一般的になりつつあります。生成AIによる回答内で認知・引用されることはユーザーとの新たな接点であり、これからのビジネスにおいて無視できません。
一方で、AIクローラーによる情報収集が進むことで、意図しない学習利用やサーバー負荷の増加といった課題も生じています。そのため、検索流入だけでなく、AIによる情報利用も踏まえながら、自社に合った公開・制御方針を検討することが重要です。
監修者の一口ポイント
AIクローラーは、SEOやLLMOと切り離して考えるものではなく、すべての情報流通の入口として機能します。つまりAIクローラー対策は、SEOとLLMOの前提条件ともいえる領域かもしれません。
AIクローラー対策で押さえたい運用ポイント
AIクローラー対策では、継続的な運用体制を整えることも重要です。法務・技術・監視の観点から管理を行い、自社サイトに合った方針を定期的に見直しましょう。
利用方針・利用規約を整備する
AIクローラー対策では、利用方針や利用規約の整備も重要です。たとえば、スクレイピング禁止条項や著作権表示、AI学習利用に関する方針を明記することで、サイト運営者としての意思表示につながります。
法的拘束力には限界があるものの、無断利用への抑止や、社内での判断基準の統一にも役立ちます。とくに、複数部署でサイト運営を行っている場合は、公開ルールを事前に整理しておくことが重要です。
AIクローラーの制御環境を見直す
AIクローラーの仕様や制御方法は変化しているため、設定内容を定期的に見直すことも重要です。robots.txtだけでなく、llms.txtのような新しい仕組みも登場しており、今後は制御方法が多様化する可能性があります。
過去に設定した内容を放置すると、現在の運用方針とズレが生じるケースもあります。最新動向を確認しながら、自社サイトに適した制御環境を整えましょう。
継続的にアクセス状況を監視する
AIクローラー対策では、継続的な監視も欠かせません。サーバーログやアクセス解析ツールを確認することで、どのAIクローラーがアクセスしているか把握できます。アクセス頻度や挙動の変化を監視することで、サーバー負荷対策や設定見直しにもつながるでしょう。
定期的に確認を行える担当者を決めたり、必要に応じて外部パートナーを活用したりする体制づくりも重要です。
監修者コメント
日々進化するAIクローラーへの対策は、仕様変更や新規クローラーの登場を前提にした継続運用が必要です。定点観測と定期レビューを行うことで、目的にあわせた制御ができます。
AIクローラーに関するよくある質問
AIクローラーへの対応を検討する中で、「SEOへの影響はあるのか」「どこまで拒否すべきか」など、判断に迷うケースも多いでしょう。ここでは、AIクローラー対策でよくある質問をまとめて紹介します。
Q. AIクローラーと従来の検索エンジンの違いは何ですか?
A. AIクローラーは、生成AI向けの情報収集を目的としている点が特徴です。
従来の検索エンジンクローラーは、検索結果へ表示するためのインデックス作成を主目的としています。一方、AIクローラーは、生成AIの学習や回答生成に利用する情報収集を目的としている点が大きな違いです。
Q. AIクローラーを拒否することは可能ですか?
A. はい、特定のAIクローラーを拒否できます。
robots.txtやサーバー設定を利用することで、特定のAIクローラーを拒否できます。ただし、robots.txtはクローラー側の遵守に依存する仕組みであるため、完全な遮断を保証するものではありません。
Q. AIクローラーをブロックするとSEOに悪影響はありますか?
A. 生成AI向けクローラーのみであれば、SEOへ直接影響しないケースが一般的です。
GPTBotやClaudeBotなど、生成AI向けクローラーを拒否しても、通常の検索順位へ直接影響しないケースが一般的です。ただし、Googlebotまで遮断すると、検索結果へ表示されなくなる可能性があります。
Q. どのAIクローラーを許可・拒否すべきですか?
A. 自社サイトの目的や運用方針に応じて判断することが重要です。
独自コンテンツの保護を重視する場合は拒否を検討し、AI経由での認知拡大を狙う場合は許可する選択肢もあります。すべてを一律で設定するのではなく、クローラーごとに判断することが重要です。
AIクローラー対策は「制御と活用」の両立が重要
AIクローラー対策では、単に拒否・遮断するだけでなく、「どの情報をどこまで活用させるか」を考えながら運用することが重要です。近年は、生成AIを使って情報収集を行うユーザーも増えており、AI上で認知・引用されることが新たな接点になりつつあります。
そのため、AIクローラーの特性を理解したうえで、自社コンテンツの価値や流入戦略に応じた公開・制御方針を整理することが重要です。
ipe(アイプ)独自のAI検索可視化ツール「AKARUMI」なら、自社サイトがAIにどのように認識・引用されているのかを可視化できます。AI経由での露出状況を把握することで、「どの情報を積極的に活用させるか」「どこを制御すべきか」といった判断にも役立ちます。
また、AI検索での露出拡大やAI経由での認知獲得を本格的に目指したい場合は、ipeのLLMOコンサルティングサービスもおすすめです。AIに引用されやすいコンテンツ設計から運用支援まで、一貫してサポートいたします。





AIクローラーに文脈が省略されたまま引用されてしまうケースもあります。対策をする際は、「どの情報をAIに見せるか」を念頭に、ログ監視と公開範囲の設計をセットで考えるようにしましょう。